
Press Ctrl+ and K to search
请注意,本文编写于 280 天前,最后修改于 280 天前,其中某些信息可能已经过时。
目录
什么是indexTTS
indexTTS是一款基于深度学习的语音合成工具,支持自主上传样本音频,并输入文本进行语音合成。bilibili开源,简单好用容易上手。 github地址:https://github.com/index-tts/index-tts
如何在windows上安装indexTTS
1. 安装FFmpge
FFmpeg 是一个开源的多媒体框架,可以用来处理音频和视频文件。
- 下载安装包,在浏览器中输入(https://www.gyan.dev/ffmpeg/builds/packages/ffmpeg-7.1.1-full_build.7z)
- 配置环境变量,将FFmpeg的bin目录添加到系统的PATH环境变量中。
- 验证安装,在命令行中输入
ffmpeg -version,如果出现版本信息,则表示安装成功。
2. 创建一个Python虚拟环境
这里使用conda来创建虚拟环境。
- 打开命令行,输入以下命令创建虚拟环境:
conda create -n indexTTS python=3.10
- 激活虚拟环境:
conda activate indexTTS
后续的所有操作都在这个虚拟环境中进行。
3. 安装Pynini
Pynini是一个基于开源的FST(有限状态机)库的Python库,用于构建和操作有限状态转换器。
在语音识别和合成系统中,Pynini被广泛用于构建语言模型和声学模型。
conda install -c conda-forge pynini==2.1.6 pip install WeTextProcessing --no-deps
4. 安装Pytorch
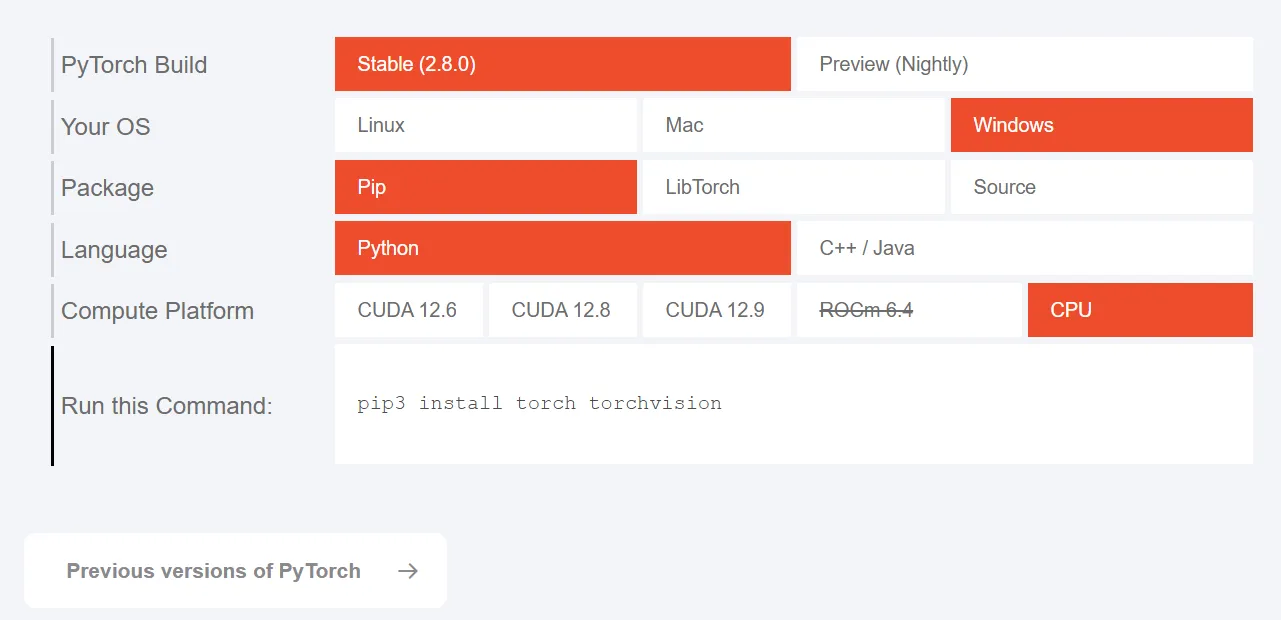
- 访问Pytorch官网 https://pytorch.org
- 选择适合你系统的版本,并复制命令(有CUDA选CUDA,没有就选CPU,注意选择正确的版本)
5. 通过git拉取indexTTS代码
最新2.0版本的indexTTS代码可以通过git进行获取。
git clone https://github.com/index-tts/index-tts.git
如果需要使用1.5或者1.0版本的indexTTS请到 https://github.com/index-tts/index-tts/releases/tag/v1.5.0 下载旧版本
6. 安装依赖
- 进入index-tts目录
cd index-tts
- 安装
pip install -e . pip install gradio modelscope
7. 下载模型
选择一个版本进行下载,并且使用之前安装的modelscope进行下载
# 1.0版本 modelscope download --model IndexTeam/Index-TTS --local_dir models/IndexTTS # 1.5版本 modelscope download --model IndexTeam/IndexTTS-1.5 --local_dir models/IndexTTS-1.5 # 2.0版本 modelscope download --model IndexTeam/IndexTTS-2 --local_dir models/IndexTTS-2
等待安装完成。
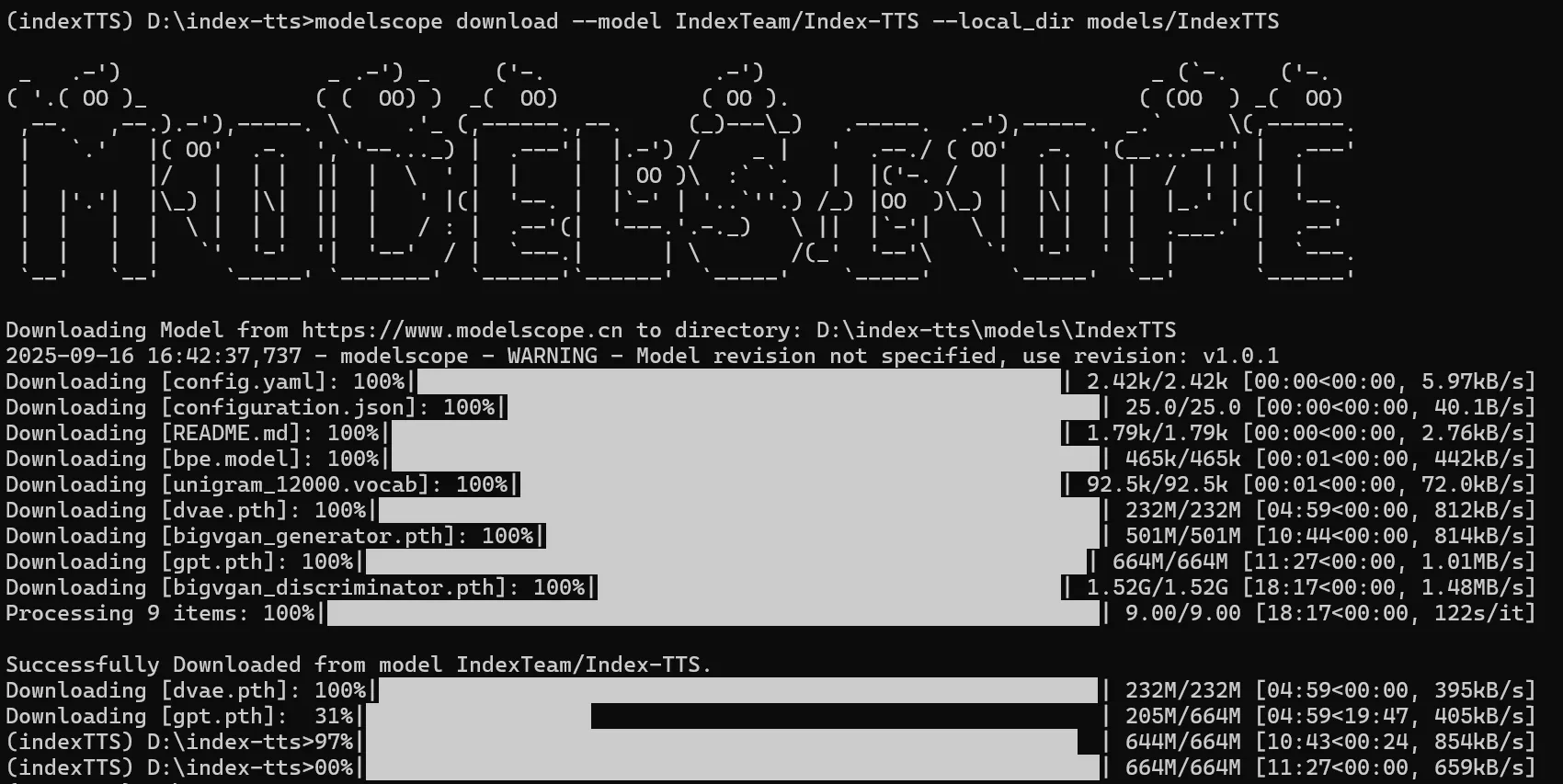 如果你发现界面卡在类似这样的界面,那么大概率是显示的问题,按几下回车,如果出现了输入行,那么说明是已经下载好了。
如果你发现界面卡在类似这样的界面,那么大概率是显示的问题,按几下回车,如果出现了输入行,那么说明是已经下载好了。
这时已经将模型下载到了项目根目录/models/IndexTTS目录下。
8. 运行
# 1.0 python webui.py --model_dir models/IndexTTS # 1.5 python webui.py --model_dir models/IndexTTS-1.5 # 2.0 python webui.py --model_dir models/IndexTTS-2
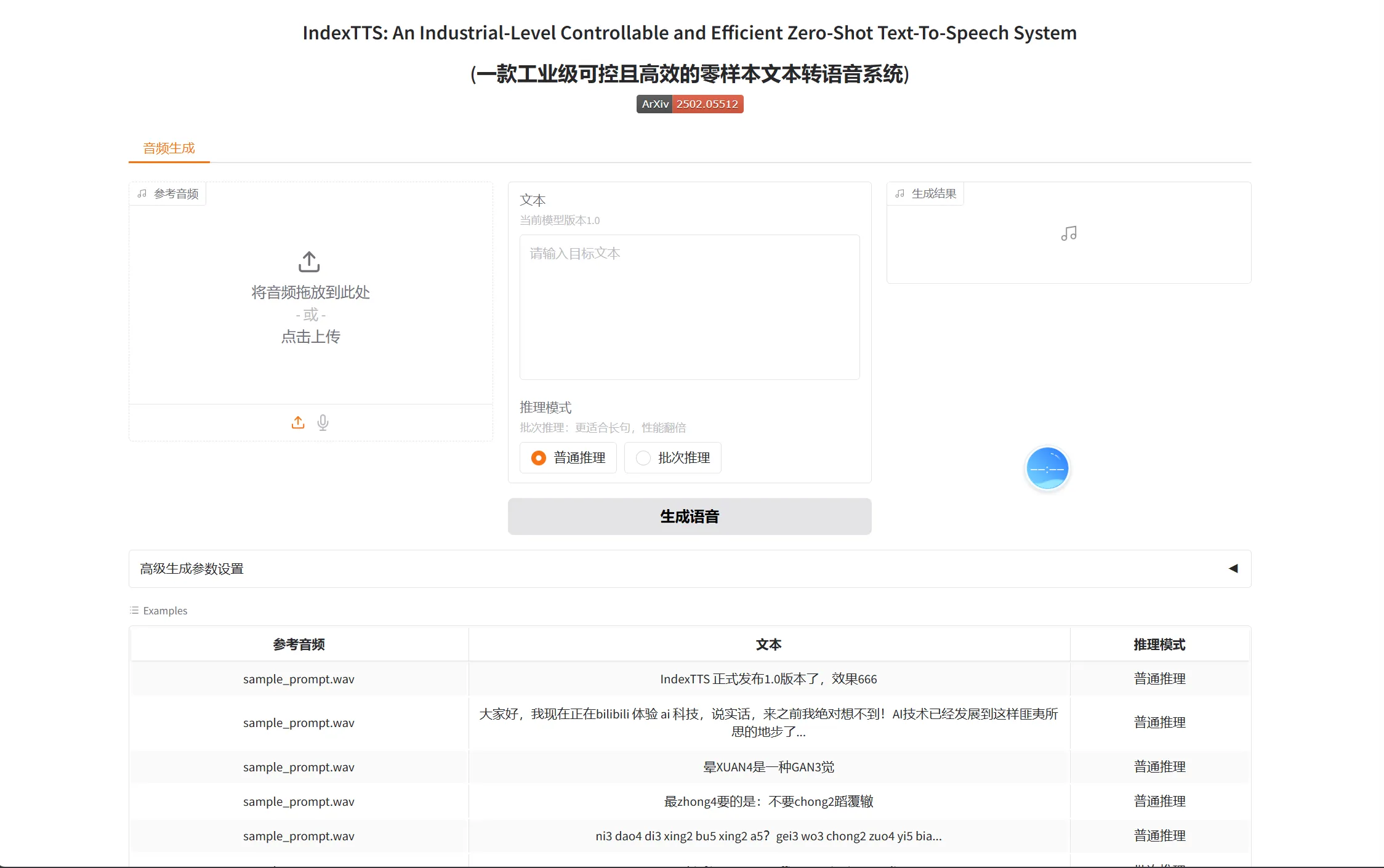
9. 访问
打开浏览器,输入 http://127.0.0.1:7860 ,即可访问indexTTS的webui界面。
本文作者:hwy2580
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录